How to implement get_data_for_table
The get_data_for_table method returns data for each record of each table defined in your metadata. Its output is an ExtractionData object which is imported directly from the celoxtractor.types module. As displayed below, ExtractionData contains a list (all records) of lists (all fields for a specific record).
Important: the order of columns in the output of get_data_for_table must be identical to the order of columns in the output of get_metadata.
- Here is a sample get_data_for_table implementation to illustrate the data structure:
from datetime import datetime from celoxtractor.extractor import CelonisExtractor from celoxtractor.types import Table, Column, ExtractionData from celoxtractor.utils import get_variable_from_filter class TestExtractor(CelonisExtractor): # Metadata is defined as explained in the "How to implement get_metadata" section def get_metadata(self): users_table = Table("users") users_table.columns = [Column("name", "STRING"), Column("user_id", "INTEGER"), Column("birthDate", "DATETIME")] departments_table = Table("departments") departments_table.columns = [Column("department_name", "STRING"), Column("department_id", "INTEGER")] return [users_table, departments_table] # The get_data_for table method can leverage additional arguments which are discussed in the "Advanced" sections below def get_data_for_table(self, table_name, parameters, is_delta_load, extraction_filter): # Initiate an ExtractionData object extraction_data = ExtractionData() # Depending on which table the Python Extractor user selects, define which data will be returned if table_name == "users": # Here, the data for "users" table records is hard-coded to illustrate the data structure. # Note that you could equally send a specific API request here, e.g. (see "Real-Life Example" below) extraction_data.records = [ ["user1", 1, datetime.strptime("1990-06-04 14:32:45", '%Y-%m-%d %H:%M:%S')], ["user2", 2, datetime.strptime("1987-02-34 12:47:21", '%Y-%m-%d %H:%M:%S')], ]; if table_name == "departments": extraction_data.records = [ ["Engineering", 32], ["Product Management", 12] ]; # Return the ExtractionData object containing the table's data as a list of lists return extraction_data
- And here is how it would look like in the IBC after the extraction:
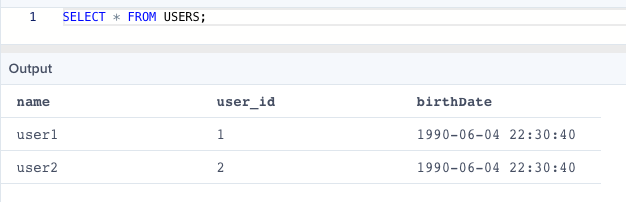
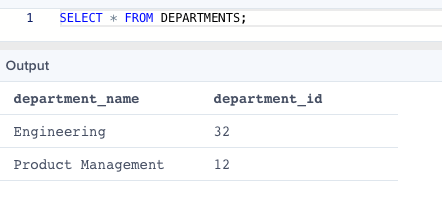
Real-Life Example
This sample Python script extracts the “sys_id” and “sys_updated_on” columns from every table of the ServiceNow API dynamically.
from celoxtractor.extractor import CelonisExtractor from celoxtractor.types import Table, Column, ExtractionData from celoxtractor.utils import get_variable_from_filter # Import additional libraries that make it easier to send API requests import requests from requests.auth import HTTPBasicAuth import datetime class ServiceNowSysIdExtractor(CelonisExtractor): # Get metadata using ServiceNow's REST API def get_metadata(self): tables = [] response = requests.get('https://dev80458.service-now.com/api/now/table/sys_db_object', auth = HTTPBasicAuth(parameters["username"], parameters["password"])).json() for record in list(response.values())[0]: table = Table(record["name"]) table.columns = [Column("sys_id", "STRING"), Column("sys_updated_on", "DATETIME")] tables.append(table) return tables # Get metadata using ServiceNow's REST API def get_data_for_table(self, table_name, parameters, is_delta_load, extraction_filter): extraction_data = ExtractionData() response = requests.get('https://dev80458.service-now.com/api/now/table/' + table_name, auth = HTTPBasicAuth(parameters["username"], parameters["password"])).json() for record in list(response.values())[0]: extraction_data.records.append([record["sys_id"], datetime.datetime.strptime(record["sys_updated_on"], '%Y-%m-%d %H:%M:%S')]) return extraction_data
Advanced: How to use the is_delta_load parameter
Each extraction is executed as either full or delta load. To enable your Python Extractor to handle both full and delta loads, you can implement the is_delta_load parameter (boolean; also comes directly with Celoxtractor). For example:
def get_data_for_table(self, table_name, parameters, is_delta_load, extraction_filter): # Define the initial API endpoint url = 'https://my-company.com/internal/api/get_event_logs' # Depending on whether you want to execute a delta or full load, add different request parameters if is_delta_load: # For delta loads, only extract records that were updated after one day ago url += "?updated_after=" + (datetime.datetime.now() - datetime.timedelta(days = 1)).strftime("%y%m%d") else: # For full loads, extract all records created in 2020 url += "?created_after=20200101" # Fetch the data response = requests.get(url).json() # TODO parse the response and return records
After implementing is_delta_load in your script, you can flexibly trigger full or delta loads directly from the IBC:
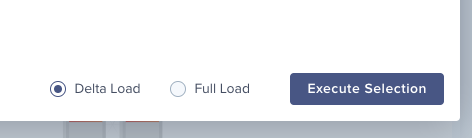
Advanced: How to use extraction filters
Celoxtractor allows you to access all custom filters that you have defined in the IBC’s extraction configuration. To achieve that, Celoxtractor passes those filters in the extraction_filter field (SQL format). Below is an example to illustrate how that works.
- We define the filters in the native IBC environment as follows:
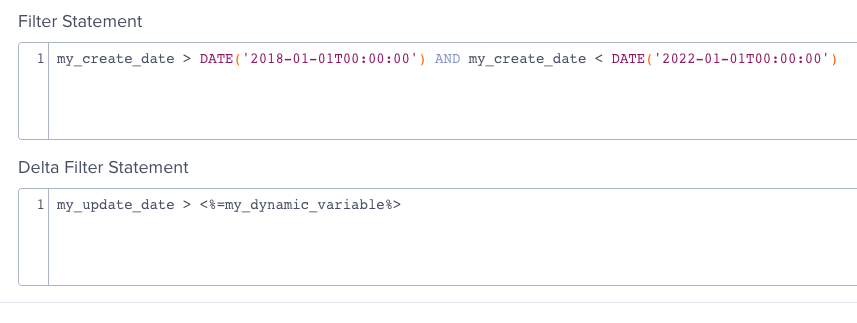
- In full mode, the value of extraction_filter for those filters will then be:
( my_create_date > '2018-01-01 00:00:00' AND my_create_date > '2022-01-01 00:00:00' )
- In delta mode, its value will be:
( ( my_create_date > '2018-01-01 00:00:00' AND my_create_date < '2022-01-01 00:00:00' ) AND my_update_date > '2020-09-07 01:08:30' )
- To use the filters in your Python script, you can parse the extraction_filter yourself or just use get_variable_from_filter (comes with celoxtractor.utils module). For example:
from celoxtractor.utils import get_variable_from_filter def get_data_for_table(self, table_name, parameters, is_delta_load, extraction_filter): # Define the initial API endpoint url = 'https://my-company.com/internal/api/get_event_logs' # Depending on whether you want to execute a delta or full load, add different request parameters if is_delta_load: # For delta loads, only extract records that were updated after the date defined as delta filter in the IBC update_date_after = get_variable_from_filter(extraction_filter, 'my_update_date', '>', 'DATETIME') url += "?updated_after=" + update_date_after.strftime("%y%m%d") else: # For full loads, extract records that were created between the dates defined as filters in the IBC create_date_before = get_variable_from_filter(extraction_filter, 'my_create_date', '<', 'DATETIME') create_date_after = get_variable_from_filter(extraction_filter, 'my_create_date', '>', 'DATETIME') url += "?created_after=" + create_date_after.strftime("%y%m%d") + "&created_before=" + create_date_before.strftime("%y%m%d") response = requests.get(url).json() # TODO parse the response and return records
Advanced: How to use batching
Celoxtractor’s batching feature allows Celonis to start processing extraction data in the background while your Python Extractor script continues to run. That can be helpful to resolve various memory exceptions and fasten your extraction.
Batching is introduced via the flush_extraction_data method as shown in the example below.
def get_data_for_table(self, table_name, parameters, is_delta_load, extraction_filter): extraction_data = ExtractionData() if table_name == "users": # Records for the first batch extraction_data.records = [ ["user1", 1, datetime.strptime("1991-01-01 14:32:11", '%Y-%m-%d %H:%M:%S')], ["user2", 2, datetime.strptime("1992-02-02 20:30:22", '%Y-%m-%d %H:%M:%S')], ["user3", 3, datetime.strptime("1993-03-03 14:32:33", '%Y-%m-%d %H:%M:%S')] ] # Subtable records for the first batch extraction_data.sub_table_records = { "user_login": [ [1, datetime.strptime("2001-11-25 14:32:11", '%Y-%m-%d %H:%M:%S')] ] } # This line sends current data to Celonis and returns you a new and empty ExtractionData object extraction_data = self.flush_extraction_data(extraction_data) # Records for the second batch extraction_data.records = [ ["user4", 4, datetime.strptime("2004-04-24 20:30:44", '%Y-%m-%d %H:%M:%S')], ["user5", 5, datetime.strptime("2005-05-25 14:32:55", '%Y-%m-%d %H:%M:%S')] ] return extraction_data